



L’IA che la PA italiana deve costruire: oltre i progetti, serve un ecosistema
Perché la PA italiana rischia di restare con tanti progetti isolati e pochi risultati sistemici, tra iper-regolamentazione e la lezione britannica.

✍️ Editoriale

La Pubblica Amministrazione italiana si presenta oggi come un protagonista tecnologico più avanti di molte aziende private nell’adozione di soluzioni di intelligenza artificiale. Lo dimostra il recente report AgID-Politecnico di Milano, che ha censito 120 progetti attivi tra 45 amministrazioni centrali e gestori di servizi pubblici. Quasi metà dei progetti è orientata a migliorare infrastrutture sociali e sostenibili, con l’uso dominante del machine learning tradizionale e un forte impiego di chatbot e assistenti virtuali basati sul linguaggio naturale.
I numeri di bilancio? In media 3,2 milioni l’uno, finanziati perlopiù con fondi ordinari integrati dal PNRR; metà degli affidamenti passa da gare ICT generiche e il 12 % arriva da proposte “spontanee”, con rischio di vendor lock-in.
Durata standard: tre anni. Valore contrattuale medio: 19 milioni.
Sul fronte dati prevalgono archivi interni non strutturati, qualche esperimento con sintetici e una preoccupante scarsa attenzione agli standard di qualità. Solo un progetto su cinque definisce KPI d’impatto: senza metriche, la “trasformazione” rischia di restare intrappolata nei report. Consola -in parte- il capitolo rischi: il 95 % delle soluzioni non ricade nelle fasce “alto rischio” dell’AI Act.
Sotto la superficie dei numeri brillanti si nasconde un problema strutturale: la Pubblica Amministrazione fatica a costruire un vero ecosistema integrato. Molti progetti restano isolati, con scarsa attenzione alla qualità dei dati, alla definizione di metriche d’impatto e alla formazione interna delle competenze. Circa la metà del lavoro viene affidata a consulenti esterni, con università e centri di ricerca relegati a ruoli marginali. Il rischio è di ritrovarsi con un arcipelago di prototipi “isola”, incapaci di trasformare la PA in un sistema digitale coeso e scalabile.
A complicare il quadro, l’AI Act europeo si profila come un’iper-regolamentazione che rischia di soffocare l’innovazione più che di proteggerla. La normativa, nata con l’intento di governare l’IA in modo etico e trasparente, appare però oggi inadatta a una tecnologia che evolve più velocemente delle leggi e degli standard tecnici. Bruxelles si trova a dover rinviare parti essenziali dell’AI Act perché le istituzioni non sono pronte a produrre regolamenti all’altezza dei modelli emergenti. Il risultato è un rischio di burocratizzazione eccessiva e di fuga degli investimenti verso ecosistemi più agili come Stati Uniti e Israele.
La verità, che pochi a Bruxelles dicono a voce alta, è che forse l’IA non è ancora regolabile nei termini classici del diritto. È un oggetto politico instabile, come la finanza quantistica o il cambiamento climatico: lo si può monitorare, mitigare, adattare, non ingabbiare in categorie giuridiche fisse. Posticipare l’AI Act non è un dettaglio tecnico: è un segnale di fragilità di fronte a una tecnologia che rinnova se stessa ogni sei mesi.
In questo contesto, una lezione arriva dal Regno Unito, dove il Cabinet Office ha sviluppato Extract, un’app basata su Gemini di Google che automatizza completamente l’analisi di documenti complessi e moduli in ambito di concessioni edilizie. Nei test pilota il tempo medio di analisi di un dossier è crollato da circa due ore a meno di un minuto, liberando i planner per le valutazioni sostanziali e non per la caccia alle coordinate su carta velina. Con circa 350.000 domande di pianificazione edilizia vengono presentate all'anno in Inghilterra, fate voi i conti rispetto al risparmio in termini economici e di tempo.
È evidente un paradosso: un algoritmo targato Big Tech entra nelle viscere degli archivi pubblici per far correre un processo che, fino a ieri, prosperava sulla lentezza cartacea. Più efficienza, certo, ma anche nuove domande su privacy, trasparenza degli output e dipendenza da modelli proprietari—temi già all’ordine del giorno nelle trattative sull’AI & Cloud Framework che Londra sta negoziando con i fornitori strategici.
La digitalizzazione di alcuni processi della PA però sta aprendo strade inaspettate. L’introduzione del PCT (Processo telematico) in ambito giustizia, ha obbligato la macchina della giustizia a digitalizzare e depositare presso i tribunali solo in formato digitale. Sono tutti dati in pancia al Ministero di Grazia e Giustizia. Così come per la giustizia, questo processo sta avvenendo con i Fascicoli Sanitari Elettronici -su cui però si paga la frammentazione del sistema sanitario regionale e un avvio ritardato-.
Questa mole immensa di dati strutturati, dice l’ufficio Responsabile del Servizio per l'informatica e Responsabile Protezione Dati del Consiglio di Stato, è oro colato per addestrare modelli di AI sovrani che garantiscano privacy ai cittadini e permettano un efficientemento decisivo della macchina della PA.
L’Italia potrebbe trarre ispirazione dall’approccio più pragmatico UK, meno vincolato da regolamentazioni paralizzanti o inserirsi dentro quello che sarà il disegno europeo, ma una cosa è certa: il futuro della PA digitale non è sta nell’adozione delle tecnologie più avanzate, ma nella capacità di costruire un ecosistema integrato, sostenibile e governato con competenze interne solide e partnership strategiche di qualità.
Serve quindi un cambio di passo nel procurement pubblico, un maggiore investimento in formazione specialistica e figure dedicate come l’AI Officer, e soprattutto un equilibrio tra regole e flessibilità che eviti di trasformare l’innovazione in un incubo burocratico. Solo così potremo far uscire la Pubblica Amministrazione italiana dal limbo dei prototipi-isola e farla diventare un modello di eccellenza digitale, capace di migliorare davvero la vita di cittadini e imprese.
⚖️ Giustizia Digitale
AI e tribunali: la pericolosa illusione dei pareri legali generati dall’AI generalista

L’intelligenza artificiale generalista, pur evoluta, mostra limiti pericolosi nel fornire pareri legali affidabili. Anthropic ha pubblicato il "manuale di istruzioni" interno di Claude 4. Lo potremmo definire il prompt "padre". Il "carattere" che gli sviluppatori hanno dato a Claude. Un sistema trasparente all'utente che però condiziona le risposte e le attività che svolge Claude. Una sorta di codice di comportamento che dice a Claude come rispondere, cosa evitare e come ragionare. Sul copyright sono ferrei: mai più di 15 parole consecutive da fonti protette. E per ben tre volte nel prompt “padre” specificano che "Claude non è un avvocato".
Il problema rimane reale ed è sistemico: in un atto difensivo italiano compaiono un articolo giuridico-fantasma e persino un autore inventato, prodotti da un sistema GenAI e copiati pari pari dall’avvocato. Non è un caso isolato: ad aprile il tribunale di Firenze ha smascherato sentenze di Cassazione mai esistite create da un chatbot e spacciate come precedenti.
Studi mostrano che gli errori nei modelli legali verticali oscillano tra il 17% e il 33%, mentre i modelli generalisti raggiungono allucinazioni fino all’88% . Per questo recentemente nel Regno Unito i tribunali mettono in guardia gli avvocati contro l'uso di intelligenza artificiale generativa senza controllo, a seguito di due recenti casi simili in cui gli avvocati hanno presentato precedenti che non esistevano.
Gli errori giudiziari possono ribaltare sentenze o portare a sanzioni penali, per questo gli atti giudiziari sono considerati ad “alto rischio” secondo l’AI Act. Per questo motivo gli Ordini forensi si sono attivati e stanno studiando linee guida con responsabilità piena per chi deposita atti generati da AI e multe fino a 15.000 euro. Fino a quando non ci saranno sistemi affidabili con fonti certe e KPI pubblici sull’errore, è meglio affidarsi alle fonti tradizionali o a modelli specifici sviluppati su dottrina editorializzata. Quello che è certo è che la tecnologia è potente, ma va usata con consapevolezza: i tribunali non devono diventare un banco di prova per l’IA non ancora pronta a sostituire il giudizio umano.
📚 Cultura
Quando le biblioteche diventano dataset: Harvard apre (quasi) un milione di libri alle IA
Per alimentare chatbot sempre più “affamati”, Big Tech sta rovistando tra gli scaffali polverosi: la Harvard Law School Library rilascia Institutional Books 1.0, 394 milioni di pagine scannerizzate, 254 lingue e 242 miliardi di token tratti da volumi pubblicati dal XV secolo in poi techxplore.com. Il pacchetto — disponibile su Hugging Face — offre alle IA un tesoro culturale finora escluso dal web, riducendo il rischio (e i costi legali) legato ai testi ancora coperti da copyright.
Dietro l’operazione c’è un flusso di “gifts” di Microsoft e un assegno da 50 milioni firmato OpenAI, che vede nei fondi pubblici e nelle raccolte storiche una via d’uscita alle cause intentate da autori viventi. Google, dopo anni di contenziosi, ha perfino riaperto i suoi archivi per restituire ai ricercatori i volumi di pubblico dominio digitalizzati nel progetto Google Books.
Il colpo d’occhio fa gola: meno di metà dei libri è in inglese, con un’ampia fascia di testi ottocenteschi su letteratura, diritto, agricoltura e filosofia che promette di rafforzare le capacità di ragionamento dei modelli. L’Authors Guild applaude, parlando di “democratizzazione” dell’addestramento AI, ma anche i bibliotecari avvertono: tra quelle pagine vivono teorie pseudoscientifiche e narrative coloniali che possono iniettare bias e disinformazione nei sistemi.
Se le biblioteche diventeranno i nuovi gatekeeper dei dati, la sfida sarà trasportare non solo i libri, ma anche la cura editoriale che li accompagna — altrimenti rischiamo di digitalizzare, in blocco, anche i pregiudizi dei secoli passati.
💼 Giochi
Mattel porta l’AI nei suoi giochi con OpenAI

Mattel collabora con OpenAI per integrare l’AI in Barbie, Hot Wheels e UNO, con i primi prodotti attesi entro fine 2025. ChatGPT Enterprise sarà usato per accelerare sviluppo e marketing.
L’obiettivo è creare giocattoli interattivi: piste ideate via prompt, bambole che parlano in linguaggio naturale e giochi che si adattano ai bambini.
Ma ci sono rischi: privacy infantile, norme UE sull’AI, e precedenti come Cayla, vietata in Germania. Mattel promette sicurezza con modelli locali e auditing.
Tutto si giocherà sulla fiducia dei genitori. Se funziona, sarà una rivoluzione; altrimenti, solo un esperimento costoso. Anche Lego e Hasbro si stanno muovendo.
📈 Media & Ads
Taboola sfodera “DeeperDive”: la vendetta dei contenuti
Taboola ha scelto l’attacco frontale contro i motori d’AI che divorano contenuti senza restituire traffico: con “DeeperDive”, un motore di risposta generativa integrato direttamente nei siti editoriali, la società promette di trattenere lettori e ricavi all’interno dell’“open web”. Il sistema – già in beta su USA Today e The Independent – usa un LLM addestrato sui 9 000 partner del network, mostra link agli articoli originali e inserisce annunci native accanto alle risposte.
Il CEO Adam Singolda lo presenta come “la vendetta dei contenuti”: se Perplexity e BingAI si limitano a riassumere pezzi altrui, DeeperDive vuole condurre l’utente a cliccare proprio su quei pezzi, condividendo la revenue con chi li ha scritti.
La mossa serve anche a difendere un mercato da 55 miliardi che Taboola sta cercando di strappare a Google e Meta, estendendo l’offerta oltre i classici widget raccomandazione verso formati search-style e performance ads.
Resta da capire se i lettori vedranno la differenza fra un chatbot “on-site” e uno universale, o se gli editori si accontenteranno di un AI che, pur “amica”, impacchetta comunque testi altrui sotto il marchio Taboola. In gioco c’è la sopravvivenza economica di molte redazioni: se DeeperDive riuscirà a trasformare la lotta contro l’intelligenza artificiale in un vantaggio competitivo, potremmo assistere a un raro caso in cui l’editoria batte gli aggregatori sul loro stesso campo; altrimenti, la “vendetta dei contenuti” resterà un titolo accattivante e poco più.
📱 Social
WhatsApp rompe il tabù: arrivano gli spot le pubblicità
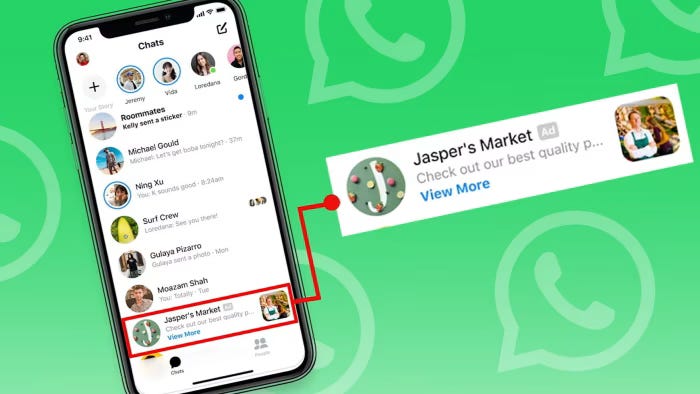
WhatsApp rompe lo storico tabù pubblicitario: dal 16 giugno le pubblicità -mirate solo su città, lingua e interazioni- appariranno nella scheda Updates, lontane dalle chat criptate, con click che aprono il dialogo diretto con il brand. Meta lancia anche abbonamenti (gratis, per ora, sulle fee) e spinta sponsorizzata ai Canali: un terzo pilastro di ricavi dopo Facebook e Instagram, sul modello “super-app” à la WeChat. La sfida è monetizzare 3 miliardi di utenti senza intaccare l’aura “privacy-first”. Come questo possa succedere è tutto da dimostrare visto che per promuovere le ad su Whatsapp, Meta utilizzerà dati personali e posizione geografica; se gli annunci migrassero nelle conversazioni, Telegram, Signal o il tanto atteso standard RCS (in sostanza controllato da Google e Apple) avrebbero un assist perfetto per acquisire nuovi utenti. Staremo a vedere.
💼 Aziende
Zhiyitech: l’“algoritmo del guardaroba” cinese che vorrebbe sostituire gli stilisti
Nata a Hangzhou da un team ex-Silicon Valley, Zhiyitech offre un SaaS che rastrella in tempo reale foto, prezzi e vendite da marketplace globali (Amazon, TikTok Shop, Temu, Shein, ecc.) e da 5.000 fashion-e-shop indipendenti, macinando 23 milioni di prodotti e 300.000 store Shein per prevedere trend, tessuti e palette dei prossimi bestseller.
Sul fronte business la startup, che ha già raccolto quasi 100 milioni di dollari in tre round, punta ora alla supply-chain-as-a-service: un “one-stop OS” che va dal design al piccolo lotto, così da vendere non solo insight ma produzione flessibile alle stesse aziende che analizza.
💊Pillole
Salesforce blocca le nuove assunzioni di ingegneri grazie agli “incredible productivity gains” ottenuti con gli strumenti AI. Amazon preparerà tagli di posti di lavoro per l’efficientamento tramite intelligenza artificiale.
L’AI di Musk brucia oltre 1 miliardo di $ al mese in costi operativi e infrastrutture.
Volvo reinventa la cintura di sicurezza integrando l'AI.
Due ex dirigenti tech di Meta e Palantir si uniscono allo staff della Riserva dell’esercito per guidare l’innovazione in ambito cloud, dati e cybersecurity.
Le società di monitoraggio web NetBlocks e Cloudflare registrano un blackout nazionale di Internet in Iran con oltre il 50% del traffico internet interrotto, forse per controllare le proteste.
l’ESA, L’agenzia spaziale Europea, cerca 1 Miliardo di dollari in finanziamenti per finanziare una costellazione satellitare dual-use per comunicazioni sicure e sorveglianza militare: l’alternativa europea a Starlink.
Netflix aggiungerà canali TV tradizionali alla sua offerta dalla prossima estate 2026, unendo live broadcast e catalogo on-demand in un’unica piattaforma.
L'indagine annuale sui consumatori digitali di Deloitte ha molti dati utili, in particolare su come le persone stanno usando e comprendendo (o meno) l'IA generativa.
🎬 Pop
La BIC Cristal, nata nel 1950 quando Marcel Bich perfezionò il brevetto Bíró, è diventato il prodotto più venduto di sempre: oltre 100 miliardi di pezzi (57 al secondo) grazie a un prezzo stracciato e allo slogan “writes first time, every time”. Il segreto sta in dettagli invisibili ma essenziali: fusto esagonale che non rotola, finestrella per controllare l’inchiostro, cappuccio ventilato per evitare il soffocamento dei bambini, foro di compensazione che equilibra la pressione in cabina aerea.
Ogni dettaglio è ingegnerizzato per sparire: nessuna ricarica, nessuna manutenzione, nessun upgrade. La Cristal resta lì dopo 75 anni, immutata, a ricordarci che la vera user experience è la sparizione dell’oggetto capace di fare una cosa sola come nessun altro - scrivere - senza “allucinazioni” e senza sbagliare -quasi- mai.
Ti piace la newsletter? Condividila con i tuoi contatti.